

Julien Guinot (ECL2018) : Comment améliorer l'apprentissage de la musique par les IA
Julien Guinot (ECL2018) est doctorant au Centre de formation doctorale en IA et musique (AIM) de la Queen Mary University of London. Ses travaux de recherche qui visent à améliorer l’apprentissage auto-supervisé de la musique par les modèles d’intelligence artificielle, ont retenu l’attention des organisateurs de l'ISMIR 2024, parmi les plus grands forums pour les universitaires, les chercheurs, les praticiens et les participants de l'industrie dans le domaine de la recherche en informatique et musique (Music Information Retrieval). Avant de faire le voyage à San Francisco en novembre prochain pour présenter ses recherches, Julien a accepté de répondre à nos questions.
Technica : Bonjour Julien. A observer ton parcours, il semble que la musique donne le La de la majorité de tes activités, y compris pendant ta scolarité à l’ECL. A quel moment, as-tu commencé à envisager d’y consacrer la suite de tes études et pourquoi pas ta future carrière professionnelle ?
Il m’a été évident assez rapidement a travers a la fois mes expériences musicales a l’ECL (Décibels, Commuz’...) et mes stages que je serais beaucoup plus épanoui dans ma carrière si celle-ci était liée à ma passion. J’ai donc su très vite qu’une composante musicale guiderait mes choix professionnels. Quant à lier l’intelligence artificielle et la musique, l’idée est apparue pendant le premier confinement et s’est confirmée pendant mon TFE chez Groover - expérience qui m’a orienté vers ma trajectoire actuelle.
Technica : Le choix de poursuivre ta formation sur une thèse était-il une évidence pour toi ? Qu’est-ce qui a motivé ta décision ?
Au contraire, j’étais indécis jusqu'à quelques mois après la fin de mes études a l’ECL. D’une part parce que je ne savais pas si la recherche serait un mode de travail qui me correspondrait et de l’autre, parce que les seuls sujets de recherche pouvant porter sur la musique dont j’avais connaissance étaient en acoustique – sujet qui ne m’intéressait plus à ce stade. C’est pendant mon TFE que j’ai lu les premiers articles scientifiques de la communauté ISMIR (articles liant IA et musique). L'absence de sujet de recherche incorporant la musique restait un frein. Une fois cette barrière disparue, le chemin s’est ouvert et j’ai entamé mes recherches pour trouver un sujet et un groupe de recherche tout en travaillant en tant que data scientist freelance pour Believe.
Technica : Peux-tu nous présenter le sujet de ta thèse ?
Pour résumer, ma thèse s’intéresse aux représentations de la musique qu’apprennent les modèles d’IA: lorsqu'un modèle d’IA apprend à effectuer une tâche musicale, il internalise une représentation numérique de la musique qui est encore relativement opaque aujourd'hui. Les questions que pose ma recherche sont : comment incorporer de nouvelles stratégies d’apprentissage et de connaissances du domaine de la musique dans l'entraînement peut-il rendre ces représentations plus interprétables et adaptées aux interactions humaines? Quels nouveaux mécanismes d'interaction peut-on créer pour mieux utiliser ces représentations?
Technica : Peux-tu nous expliquer ta méthode dite « Semi-Supervised Contrastive Learning » ?
Le semi-supervised contrastive learning est une nouvelle méthode que je propose dans mon premier article qui est un outil pour construire des représentations plus musicalement informées. Avec cette méthode, en injectant une quantité minimale de données annotées (supervised contrastive learning), on peut guider les représentations acquises avec le self-supervised contrastive learning vers des représentations contenant de manière explicite l’information présente dans les données annotées.
Technica : Quelles peuvent en être concrètement les applications futures ?
Concrètement, une telle méthode (ou plus généralement des méthodes qui permettent de comprendre comment quel concept musical est contenu dans une représentation d’un modèle) est d’une grande utilité pour l’exploration et l’analyse de catalogues musicaux, des modèles génératifs plus adaptés aux artistes et producteurs, et la recommandation pour les services de streaming. Toutes ces applications utilisent des représentations musicales issues de modèles d’IA, et des interactions telles que “j’aime ce morceau mais j’aimerais écouter un morceau plus énergique dans le même style” sont pour l’instant difficiles à modéliser. Ma recherche cherche à combler entre autres ce besoin en proposant de nouvelles architectures de modèles, de nouvelles techniques d'entraînement, et de nouveaux médiums d’interaction avec les représentations.
Technica : Comment se déroulent tes travaux de recherches ? Est-ce un travail solitaire ou collaboratif ?
Un mélange des deux. C’est avant tout un travail de développement informatique et de lecture. Certains projets sont en collaboration en fonction des affinités de recherche dans mon groupe de recherche, d’autres sont solitaires. Ma recherche est grandement facilitée par le soutien d’Universal Music Group, qui possède un des plus grands catalogues de musique de grande qualité annotée professionnellement auquel j’ai accès pour ma recherche.
Technica : Tu as partagé sur Linkedin cette infographie. Peux-tu nous la commenter pour mieux comprendre tes recherches ?
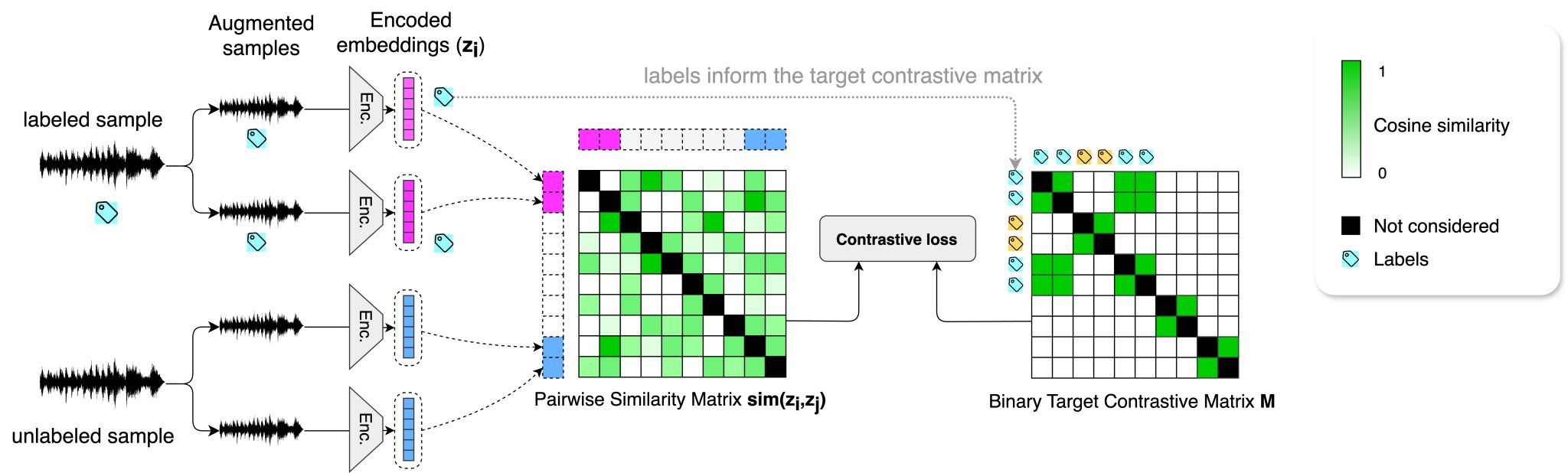
Cette infographie est un résumé de la méthode proposée dans mon article Semi-Supervised Contrastive Learning of Musical Representations”. L’apprentissage contrastif dit self-supervised apprend à maximiser (en musique) une métrique de similarité entre deux morceaux de musique similaires. Pour ce faire, un modèle est entraîné pour reconstruire une matrice de similarité par paires (part de la matrice de droite sur l’infographie sans labels) entre deux extraits d’un même morceau de musique. Cette méthode est efficace mais limitée par le choix des extraits à comparer, puisqu’on ne peut garantir sans information externe la similarité de deux morceaux de musique choisis au hasard.
La méthode que nous proposons dans notre article consiste à modifier la matrice de similarité cible en utilisant les données annotées disponibles. Ainsi, au lieu d’apprendre à maximiser la similarité entre extraits d’un même morceau, le modèle apprend à maximiser la similarité entre extraits partageant des annotations similaires - i.e. guider le modèle vers une compréhension musicale de la similarité. La méthode spécifique que je propose permet d’utiliser à la fois les données annotées et non annotées pour ne pas perdre le pouvoir du volume supérieur de données non annotées. La matrice de droite est ainsi augmentée avec des cibles positives hors de la diagonale qui guident le modèle vers la métrique de similarité voulue. Pendant l'entraînement, la matrice estimée par le modèle (a gauche) est comparée a la matrice cible pour optimiser le modèle.
Technica : Quels sont les rôles respectifs des Dr. György Fazekas, Dr. Emmanouil Benetos et de Elio Quinton d’ Universal Music Group ?
Ce sont mes superviseurs de thèse - Deux académiques et un industriel. Sur ce papier en particulier, ils m’ont conseillé sur les expériences à effectuer et m’ont beaucoup aidé à améliorer la qualité de l’écriture scientifique. En général, ils sont d’une aide et d’un soutien exceptionnels sur tous les sujets de ma thèse, de la validation de mes idées de recherche bizarres à l’analyse plus fine des résultats obtenus.
Technica : Quels sont les défis et difficultés que tu rencontres dans tes travaux ?
La recherche est un milieu nouveau pour moi et j’ai la chance d’avoir d’excellents encadrants et un groupe de recherche exceptionnel qui me permet de minimiser les difficultés rencontrées (pour le moment). La recherche en IA, même en musique, est un milieu très actif, et comme beaucoup de chercheurs il m’est arrivé d’avoir une idée au jour J et de voir un article reprenant exactement cette idée au jour J+1. Cela fait partie du jeu et c’est aussi un aspect de ce domaine que je trouve passionnant - mais il est difficile d’avoir des idées assez innovantes pour que personne d’autre ne soit en train d’y penser depuis plusieurs semaines.
Technica : Qu’est-ce que représente de savoir que tes recherches ont été sélectionnées pour l’ISMIR Conference de novembre prochain ? Qu’attends-tu de cet événement ?
ISMIR est une des grandes conférences pour la recherche en IA et musique, je suis donc très heureux d’avoir un article premier auteur accepté, surtout en première année de thèse. J’ai hâte de pouvoir prendre le pouls en personne sur les idées qu’ont les chercheurs de cette communauté, et ce sera aussi l’occasion pour moi de retrouver des collègues croisés lors de précédentes expériences. J’ai aussi bien évidemment hâte de confronter mes résultats au regard d’autres chercheurs de mon domaine: ils me feront, j'espère, des retours pointilleux qui mèneront à d’autres idées de recherche.
Technica : Dans ta description sur Linkedin, tu écris « i aspire to marry the creativity and technicity of music with the creativity and technicity of AI to support artists and engineers if the music industry! » L’IA est-elle pour toi un levier de créativité alors qu’on lui reproche souvent de standardiser la création ?
C’est un sujet complexe sur lequel je ne me permettrais pas d’avoir un avis tranché. D’une part, une IA qui génère de A à Z une musique entière serait antinomique à la créativité, et pourtant c’est un domaine de recherche en pleine floraison. J’aurais tendance à dire que hors cas spécifiques, ce cas d’usage ne générerait pas beaucoup d'intérêt de la part de potentiels consommateurs. Quand bien même, un tel système serait néfaste pour certains petits artistes qui perdraient une part du marché de création de la musique qui n’est pas destinée uniquement au streaming.
D’autre part, considérer les IA génératives uniquement dans le contexte de ce cas d’usage (qui est celui qui mène à une standardisation de la créativité) est un point de vue relativement étroit, bien que légitime et venant d’une question de société très contemporaine. l’IA peut intervenir à de nombreux endroits dans le processus créatif en amont d’une musique finie, notamment de manière granulaire dans le processus de performance, de production, de mix, d’exploration ou de génération de samples, etc. Ce sont ces cas d’usage qui sont pour moi catalystes de créativité, que les artistes utiliseront (et utilisent déjà), et qui porteront la musique vers de nouveaux horizons (à l'image des premiers synthétiseurs ou consoles de mix digitales). Sans parler d’autres cas d’usage tels que la recherche, la recommandation ou l’analyse qui n’ont rien de génératif.
Le plus important à mes yeux est de rémunérer et attribuer justement les artistes dont la musique est utilisée pour entraîner les modèles que nous améliorons au quotidien dans mon domaine et qui seront utilisés à des fins commerciales. Je ne suis pas apte à proposer une idée concrète pour un tel système, mais les considérations éthiques et légales doivent évoluer de pair avec les systèmes d’IA - et pas les rattraper.
Auteur

A lire
-
- Nomination de Pascal Ray comme Directeur de l’ECLÉcole - Nomination de Pascal Ray comme Directeur de l’ECL Le 1er décembre dernier, Pascal Ray a été nommé Directeur de l’École Centrale de Lyon. Avant cette...10 janvier 2022Lire la suite >
-
- Le Cooking Lab, au coeur de Centrale LyonÉcole - Le Cooking Lab, au coeur de Centrale Lyon Le Cooking Lab est le fruit d’une collaboration entre l’École Centrale de Lyon, le Centre de...05 juillet 2022Lire la suite >
-
- Financement de la Stratégie 2022-2030 de l’ECL : les axes de développement et les grands chantiers à soutenirÉcole - Financement de la Stratégie 2022-2030 de l’ECL : les... Centrale Lyon a adopté en octobre 2022 son plan stratégique 2030 avec pour ambition de devenir le...04 décembre 2023Lire la suite >
-
- Drone à voilure fixe : les étudiants du Master aéronautique de Centrale Lyon entrent dans la course avec le projet ECLiftÉcole - Drone à voilure fixe : les étudiants du Master... A l’image de l’Écurie Piston Sport Auto, un groupe d’étudiants du Master en ingénierie aéronautique...04 janvier 2024Lire la suite >
-
- Pascal Ray : "La notion d'établissement à mission n'existe pas officiellement mais elle fait partie de nos ambitions"École - Pascal Ray : "La notion d'établissement à mission... En marge de l’entretien que Pascal Ray nous a accordé à la rentrée de septembre 2023 et qui a été...08 janvier 2024Lire la suite >
-
- Optimisation des modèles d'allocation de l'eau : Damien Berriaud (ECL2019) lauréat du concours Veolia « Ecological Transformation Awards »École - Optimisation des modèles d'allocation de l'eau :... Doctorant à l’École polytechnique fédérale de Zurich (ETH) en génie électrique et technologies de...28 février 2024Lire la suite >
-
- Promotion des études d’ingénierie dans le Rif marocain avec Anis Jaafary (ECL2022)École - Promotion des études d’ingénierie dans le Rif... Égalité des chances, mixité et diversité face à l’accès aux études scientifiques… pour devenir...15 avril 2024Lire la suite >
-
- Eolienne d'autoconsommation en kit : nouveau souffle pour l'entreprise Bonvan avec l'ouverture des précommandesÉcole - Eolienne d'autoconsommation en kit : nouveau souffle... Si le marché des panneaux solaires pour particuliers continue de se développer en France, peu...03 juin 2024Lire la suite >
-
- 8 bonnes raisons de participer au programme de mentorat de l’ACL dès la rentréeÉcole - 8 bonnes raisons de participer au programme de... En février 2024 le programme pilote de mentorat de l’ACL lancé autour de 53 binômes faisait le pari...01 juillet 2024Lire la suite >
-
- JO Paris 2024 : un doctorant de l’ECL et du laboratoire LIRIS CNRS aux côtés de l’Équipe de France de Tennis de TableÉcole - JO Paris 2024 : un doctorant de l’ECL et du... Aymeric Erades est doctorant à l’Ecole Centrale de Lyon et au laboratoire LIRIS CNRS. Vous ne l’avez...30 août 2024Lire la suite >










Aucun commentaire
Vous devez être connecté pour laisser un commentaire. Connectez-vous.